- Prologue (The Dream that Inspires All Of This Writing)
- Top Thought Directions I Would Explore If I Ever Did a PhD.
- ! Disclaimer !
- 1. Intelligence as Emergence
- 2. How do we define utility ? Features are not bugs.
- 3. How do we define the degree of out of distribution generalization?
- 4. Reasoning and Improvement through the means of Abstractions.
- 5. Finding a ImageNet moment in learning non-stationary dynamics for MARL
- 6. Causal reasoning : Secret Sauce of a Software Developer’s Debugging Superpowers.
- Conclusions
- Foot Notes
Prologue (The Dream that Inspires All Of This Writing)
I have been extremely fascinated with the concept of truly general purpose machine/software which can aid humans solve arbitrary problems. This software can potentially interface with any hardware peripherals while have capability to ingest arbitrary types of information. This is what I call a General Purpose Technology (GPT) or what Tony calls Jarvis. Many people knowing of the No Free Lunch Theorem, Godel’s Incompleteness, Undecidability and NP Completeness or even just the sheer difficulty of the problem may roll their eyes over such baked out BS. But it’s our nature as humans to dream and shoot for the stars such that we may probably hit the moon.
I recently finished my master’s degree and I got so much time in these two years to absorb the AI and ML research space. My only goal during the degree was to let my curiosity run wild and follow it without any fears of failures. To fulfill my goal I built a search engine over CS ArXiv1 and built a lot of ML models from the papers I discovered through the search engine. The goal allowed me to build and break all ideas I found interesting. The exercise of reading/building made me I fall in love with this domain. I also realized that knowledge in this domain endowed me with new superpowers and practicing it is addictive!
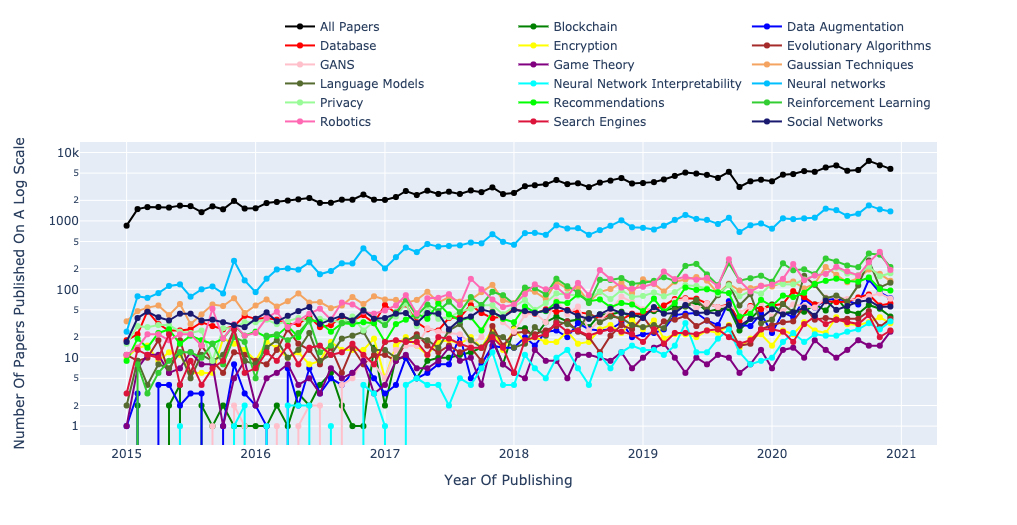
At end of the degree, I came to a very important realization. I was in a dilemma of whether it is worth doing a PhD or move towards getting a job and working in the industry. Although I love developing these fancy AI and ML systems, but I am not a huge fan of writing papers where there are so many being written (Figure above shows monthly publishing trends on CS ArXiv). The other aspect is that it’s important to find problems/research-directions worth spending 5 years of my life when there are so many topics and ideas people are exploring.
The main inspiration for this blog post comes from the idea that today’s AI is very special purpose and a lot of fancy interpolation. To reach AI like the ones we see in movies and read in books, in my opinion we need a shift in paradigm and optimize beyond the lens of just the dataset. This blog tries to list some difficult problems and directions of thought I would explore if I ever did a PhD dedicated towards this dream of a general purpose machine to help solve arbitrary problems.
Top Thought Directions I Would Explore If I Ever Did a PhD.
! Disclaimer !
All the ideas listed are the ones I would explore if I ever pursued a PhD in the next 1-2 years. Time matters. Number of papers being published is growing at an exponential rate so something’s written here may get outdated in 3-5 years. This post is not meant to be educational as a lot of stuff here is conjecture and hand wavy opinions/anecdotes. It is meant to inspire ideas and discussions. The other thing I would humbly say is that even after reading/practicing the techniques in this field for the past two years I have barely scratched the surface. The other thing I acknowledge is that many things I write here might have research already done that I am not aware of! Too Many people are working in this field have done this way longer so everything I write here should be taken with a grain of salt as my knowledge may also have gaps. Here Goes. These are the set of ideas I would explore for a PhD if I can let my creative juices just run wild.
1. Intelligence as Emergence
Inherently, all fancy machine learning models interpolate within the training data distribution based on some optimization measure. The current day trend based on this is to throw lots of data at a big model, so it can potentially interpolate from large enough patterns seen in the data. A lot of people call this fancy names like the Manifold Hypothesis2. In simplistic terms the ML model finds a smooth differentiable manifold in the space of data for which it can have a mapping in the output space. The optimization helps change this mapping between the manifold and the output space and the model helps define the mapping. The formulation of this manifold and its mapping generally happens based on the learning task and inductive biases possessed by the model. Strategies like self-supervised learning with large enough data help capture a “large size”3 of this manifold. This is one of the reasons I think why GPT-3 works so well4. With what attention mechanism is doing and what the manifold hypothesis implies, we are only creating a larger boundary to the manifold for interpolating patterns.
A recent paper from Don5 Bengio’s group included some latest SOTA techniques in the list of inductive biases incorporated in different architectural patterns. Below is a table summarizing that :
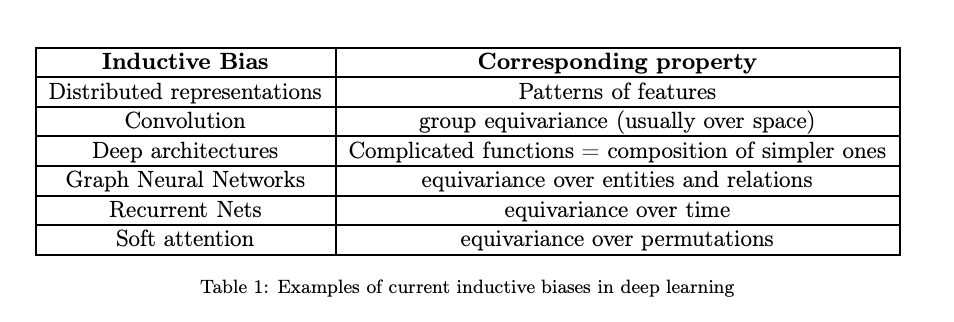
Attention is king at the current moment (May 2021) based on its popularity in the research community and its performance in various state-of-the-art tasks. Many researchers are actually saying GPT-3 like models can be “intelligent”. I don’t buy this. GPT-3 like tech makes one hell of a parser which can put many people out of jobs, but it’s not the way to reach a “General Purpose Machine”/AI.
In my opinion we may not be able interpolate our way out of complex problems. Example, In medical diagnoses, If an ML model classifies a diagnosis based on symptoms then how does it account for a totally unknown variables that account for completely different diagnosis ? How would it account for such information it doesn’t know when calibrating its responses ? How would such a “model explain to us it’s prediction in the way we understand” 6 ? We possess many such aspects to intelligence like causal reasoning or abstractions/analogizing, or common sense or intuitive physics (to name a few7) that help us tackle such problems. Many of these traits are harder to incorporate well intrinsically. Why ? Because some of these aspects need an interplay of tacit and explicit knowledge which is never readily datasetable.
Since I have been following this space, I have become a huge fan of thought directions like the ones from Fei Fei Li with a physics inspired approach of formalizing intelligence or Karl Fiston’s formalism’s on the emergence of intelligence in self-organizing systems with the free energy principle or even Kennith Stanley’s thesis of the objective itself being the problem. There is one common thing across the thesis’s of many of these people; Many of them assume that intelligence will emerge and is not “incepted” at the start. This is what really excites me as a future research direction. I can totally buy the idea that generalizable intelligence is an emergent phenomenon over it being present as a prior in a model. (I can be wrong too. Many people think that we can get to AGI by just throwing data at a model).
If I were to work on problems in AI for five years, I would consider this thought direction to influence which problems I select.
2. How do we define utility ? Features are not bugs.
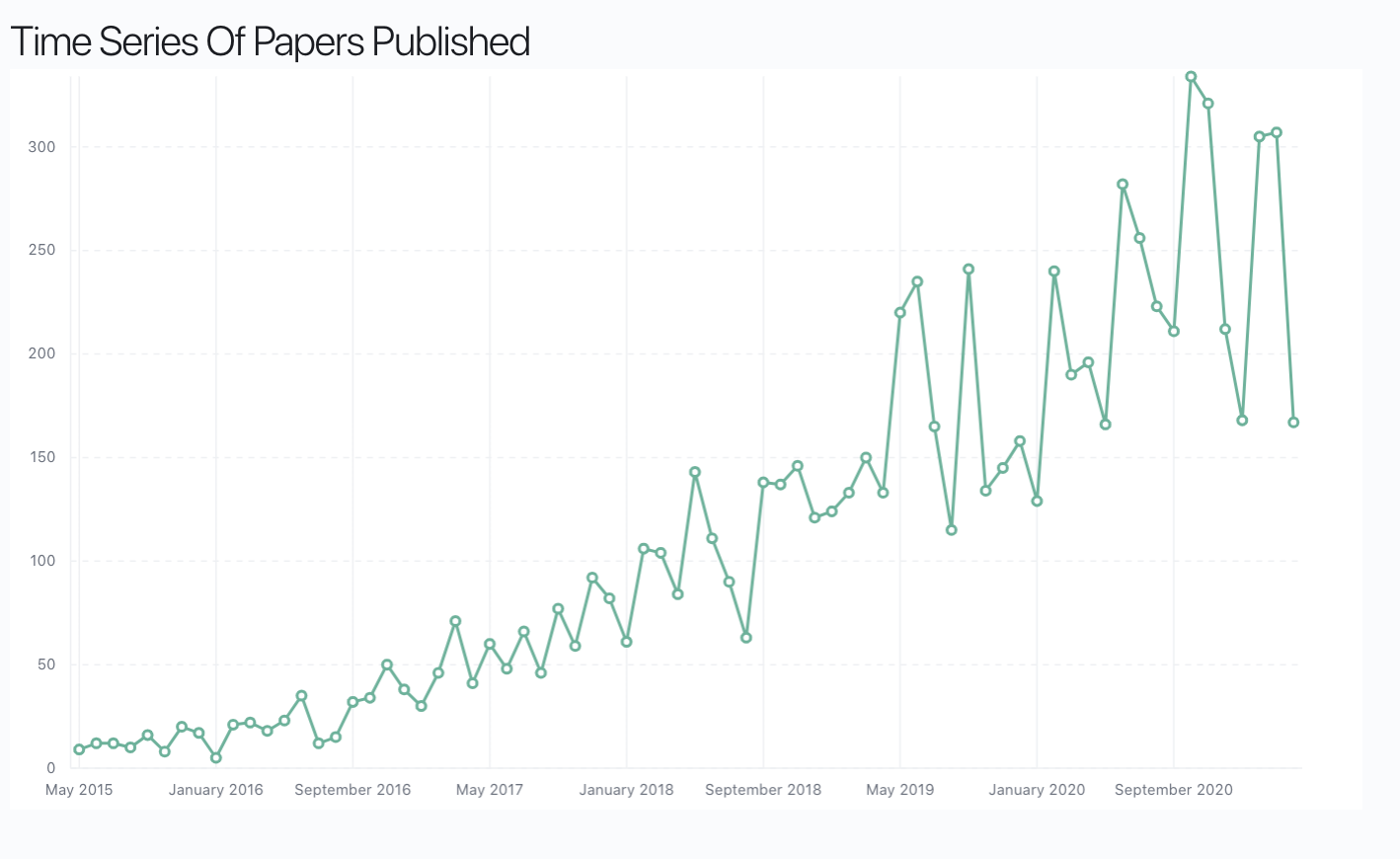
Plot of number of papers in published on RL in ArXiv.
|

What I feel when I do RL
|
The above is plot of the number of papers published on ArXiv every month on Reinforcement Learning. Ever since AlphaGo the number of people who have been publishing in RL is has grown and there are just so many algorithms with so many variations based on the way we frame problems. The biggest trick that the RL community ever played was the sleek footnote on the bottom of every paper assuming a well-behaved reward function .
Sure, to make my robot move around and get me coffee, all I need to do is find this magic function that helps me get the desired behavior, OR I’ll just give it a few years to hit/trial on sparse rewards and pray for it to work after that.
What ever people may say there are countless proofs in the brittleness and variance in RL due to parametric sensitivity creating reproducibility issue. In my opinion, RL is an amazing framework but we need a better way to understand hyper-non-convex reward/utility functions and understand the causal effects of utilities much deeper.
A famous thought experiment on the nature of utilities is the paper clip experiment.
Suppose we have an AI whose only goal is to make as many paper clips as possible. The AI will realize quickly that it would be much better if there were no humans because humans might decide to switch it off. Because if humans do so, there would be fewer paper clips. Also, human bodies contain a lot of atoms that could be made into paper clips. The future that the AI would be trying to gear towards would be one in which there were a lot of paper clips but no humans. – Nick Bostrom
The fascinating thing is that this scenario makes sense. There are many cases where RL algorithms with reward functions tuned according to our intuitions make the agent behave in ways we never imagined. If we ever want TRULY General Purpose Technology (GPT) then we need a better understanding of the implications of the way we optimize it. The best example of optimizing systems without understanding implication of optimizations is the polarization in society enabled by of a lot of social media companies optimizing their news feeds purely for engagement creating impacts in the output space (society) for which we had no proper understanding.
If we want to understand the impact of utilities we need more depth and study over the macro and microanalysis of the effects induced by the optimization of utilities (Economists can roll their eyes on this). A PhD with focus over the influence of utilities in RL would be a ripe area to make a mark on how we understand, define and compare the impact of utilities.
3. How do we define the degree of out of distribution generalization?
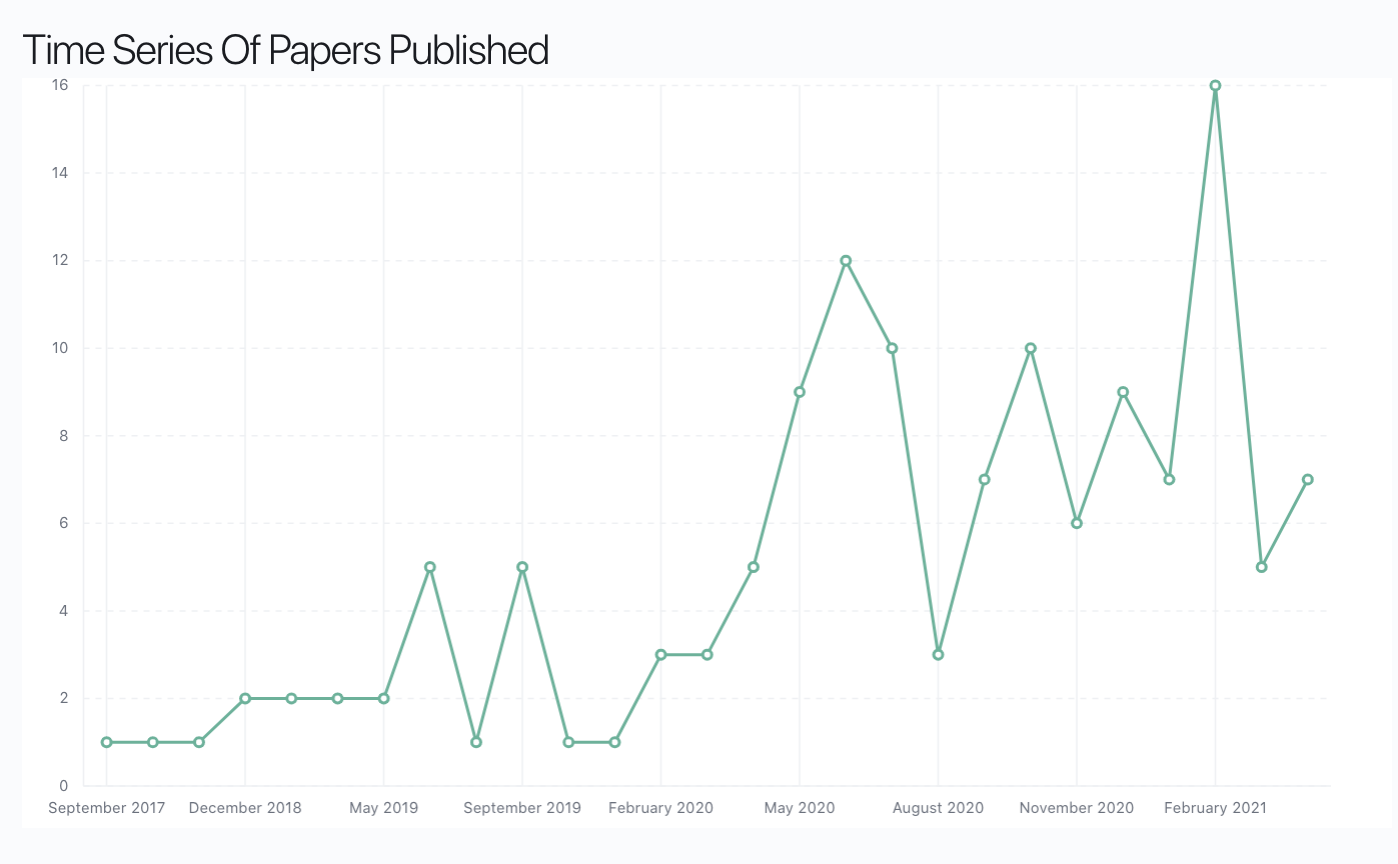
Measurement is fabulous. Unless you’re busy measuring what’s easy to measure as opposed to what’s important. - Seth Godin
Out of distribution generalization is the buzz word that comes along in many papers. The above image shows a trend plot of mentions of “out of distribution generalization” in ArXiv papers over the past few years. As generalization is very important to AI, so many papers derive esoteric reasoning and anecdotal examples on how models are generalizing. Even Don Bengio discusses so many ideas on tackling OODG with concepts from sparse factor graphs and “consciousness priors”. But as someone who wants to understand quantitatively what it means to “Generalize” I believe that finding a mathematical framework for describing the degree of generalization based on some from of task structure can make a massive difference on how we perceive AI systems.
A very good example to explain degree of generalization is an anecdote from the famous TV show Silicon Valley. In one episode Jin Yang’s company gets acquired because it creates a hot dog classifier which works very well on penile imagery. A classifier generalizing from hot-dog to penile images is a good generalization because inherently the model picked up the common biases in the data needed for the downstream task.
Ideally, if a classifier that is just seeing cats and dogs, classifies a lion or a wolf as a cat or dog respectively then I would consider this a superb generalization for that classifier. The other thing is that to measure OODG we can explicitly take into account the inherent hierarchical relationships(hot-dog -> penile imagery or cat -> lion, dog -> wolf) of different tasks/data. If there can be a mathematical framework to help describe the degree of generalization across different tasks for different models then we can have an even better understanding of the black boxes we build. The framework can derive from concepts known in math. The current day trend of SOTA chasing guides us away from what we as humans call General Intelligence because we don’t have a way to fruitfully compare degree of generalization of a model just based on test set accuracy results on some dataset.
4. Reasoning and Improvement through the means of Abstractions.
The wonderful thing about DALL-E is that it kinda shows you can encapsulate the abstract space of concepts from language and vision onto one giant codebook. To make an armchair the shape of an avocado, you need a model which can hold a latent space that allows interpolating between the visual-linguistic “concepts” of an avocado and an armchair. I would even speculate this as a way to interpolate over the space of discretized “abstractions”.
We as humans excel at discovering and organizing under abstractions to function efficiently. Examples can range from how we create organizations and assign roles based on responsibilities to when we write and refactor code for making it re-useable. Hell, we created entire sectors of industries based on how we organized the abstractions in the OSI network stack.
Yuval Noah Harari’s thesis is that our ability to communicate and organize around the abstractions we believe has made us evolve into the “intelligent” species we are. He refers to the abstractions as “fictions” we tell/believe. I feel that if machines can discover many “useful” abstractions present in our data (text, vision, code etc.) then we can use these machines for discovering so many things. A simple example: a lot of living beings have ears and eyes. An ear is an abstraction we humans categorized for making our lives easier when we communicate with each other. Abstractions occur in data all the time and we as humans excel at discovering and using them for communication/application but our AI tools still don’t hold such capabilities.
Hierarchy as Means For Reasoning
Abstractions possess hierarchy and we humans use a lot of such hierarchical properties of abstractions to perform reasoning. Anyone who has ever debugged software system, from a general first principled approach one would center out issues of a problem based on reasoning through failures according to abstractions. Meaning, you don’t need to go thinking about issues with the micro-processor, if you are getting an AssertionError. Human’s have this inherent trait to quickly discover and reason over abstractions. We see this best in human being’s abilities to debug distributed systems and operate large software infrastructure. If machines end up possessing such traits we can discover properties of information in nature and medicine that can make a massive difference to humankind.
Abstractions As Reference Frames For Recursive Improvements
Abstractions provide a reference frames for improvements or fixes. Let me give an example. Git, as a technology was created so that we can healthily experiment by building and changing abstractions while creating software. We can also use Git to find bugs introduced in the code. If abstractions are not working, Git provides a systematic way to reason about what changed to identify the source of a bug8.
Git like tools allow using abstractions as means for creating reference frames (versions) for understanding causality8 while making healthy improvements in a distributed9 way. The intuition about the way we incrementally keep writing/improving code can have amazing applications in the way AI applications optimize themselves.
If we can allow machine’s to “version” themselves, and then optimize based on how much are they improving from previous versions then we are in for a treat with what we can do with such systems. Many would now be think: Sure bro!, But what the fk are you making improvements of i.e. what utility am I optimizing for. This is something even I can’t answer but if I had 5 years to work on problems or think on ideas, this is a direction of thought I would surely explore.
5. Finding a ImageNet moment in learning non-stationary dynamics for MARL
Every time we use RL it is assumed with Markovian dynamics that take into account a stationary environment. What it means is that the transition function ( ) and reward function will be unchanged. Let’s break this down. If you put few robots learning concurrently in an environment, then the action taken by one agent affects the reward of other opponent agents, and the evolution of the state. Such a setting induces a non-stationary environment for the individual agent. This is a becomes a problem as we have more than one agent learning at the same time. Adding to the complexity, interaction between agents may be of different types. Interactions may be strategic/competitive or collaborative. This can lead to complex optimization formulations of an individual agent ’s objective function 10 as:
| $$ J^{i}\left[x_{t},\pi^{i},\pi^{-i}\right]\,=\,\mathbb{E}_{x\sim f}\,\,\Bigg[\sum_{k=t}^{T}R\left(x_{k}^{i},x_{k}^{-i},a_{k}^{i}\right)\,|\,a_{k}^{i}\sim\pi^{i}\Bigg] $$ | $$ J^{i}:S\times\Pi^{i}\times\Pi^{-i}\,\to\mathbb{R}$$ $$ S : \text{State space}\,\, x_t \in S$$ $$\forall i\,\in\,\mathcal{N},\,\mathcal{N}: \text{Number of agents}$$ $$ \Pi^{i} : \text{Agent }i\text{'s action space}$$ $$ \Pi^{-i} : \text{All other agent's action spaces}$$ $$ f : \text{Transition function}$$ $$ R : \text{ Reward function also considering other agent's state}$$ |
If we want robots and AI’s integrated in society to help humanity, we need ways to train many of them at the same time. With complex formulations like the one above there are equilibrium conditions for the optimization like a Markov Nash Equilibrium11 ( ). But reaching this with growth in number of agents and nuances of scenarios makes the optimization even harder!
We also need ways robots can learn and derive cue’s from human interaction. These direction of research involving dynamics of multiple different agents has very powerful future implications. Cracking such problems allows us to go to Mars and plant colonies using robot armies. Check out this paper if such multi-agent stationary dynamics problem interests you. I would certainly entertain this direction of thought if I could spend time on open problems in ML/AI.
6. Causal reasoning : Secret Sauce of a Software Developer’s Debugging Superpowers.
There is very famous problem in computer science called the Halting Problem. The premise of the halting problem is simple, crudely: Given a computer program, can another computer program predict if the given computer program will finish running ? Short answer, We can’t predict that. This problem is an Undecidable problem. An undecidable problem is a decision problem for which it’s not possible to construct an algorithm that will always lead to a correct yes-or-no answer. This is a quite fascinating problem because it implies that we can’t ever know ALL INPUT values that would lead any arbitrary program to keep running infinitely or stop!
Even though we may never know an exact answer about the finishing of a program, we do a decent job at reasoning about how they work and why they fail for manageable sizes of programs. But as program/project sizes grow, there is direct correlation to the amount of cognitive effort needed by a single dev to understand the code. If the size the program is larger than 10K LOC the number of hours a single dev would need to read and understand a undocument project grows exponentially.12. This becomes a real problem in the industry when the number of projects or complexity of projects grows.
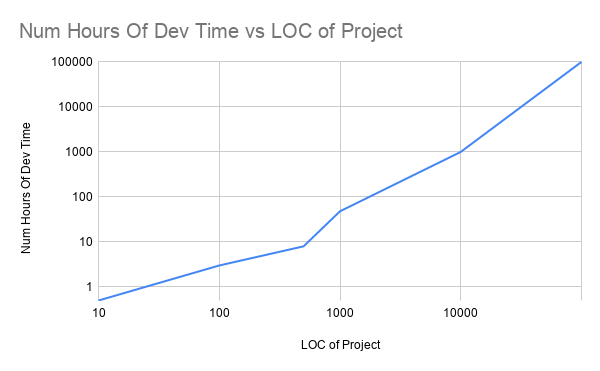
Plot of Number of Hours needed Vs Number of LOC on an undocumented project. Dont Cite this!
|
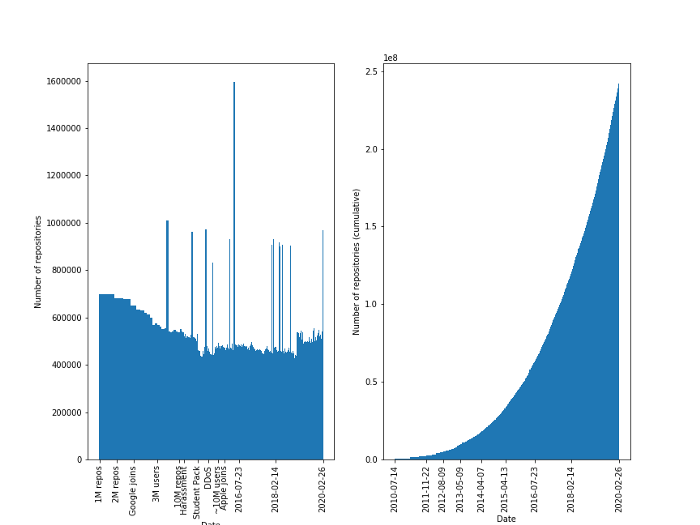
Plot of Right shows growth of number of Github repositories from 2011 to 2020. Picture from simiotics/mirror
|
Software companies around the world have projects which are never perfect. Many projects may not be best documented. Many projects have information about aspects stuck in minds of developers. So many projects may have version control that is not well done. The amount of complexity of a real world S/W project is super high and the only asset that can help tackle these problems are human developers who have the ability to understand and reason over the functioning of source code (The performance of those tasks may vary based on the developer). Even if projects are documented, really large projects have isolation of responsibility/scope for departments running the project. Many times when sizes of projects grow the disconnect between teams may lead to issues in functioning, availability or security vulnerabilities.
The main point to highlight is that bigger the systems we build, we also need to maintain them and change them. We currently use a lot of special purpose tools and test cases to make our systems work and reason about their functioning. One of the key abilities that helps us do this well enough, is about ability to predict the causality of events when we read/write code and observe software systems. More elegant example, Debugging is the art of causal reasoning in practice. Humans have the ability to infer about causality of events from the code we read/write making us quite efficient at how we create or fix software systems. Currently, we don’t have such systems which can generate code and also fix it at the same time. Creation of AI systems which have the usage of causal reasoning as an intrinsic part of the system can have great applications’ in the software industry!
Human Vs AI CTF : The Ultimate Turing Test
OpenAI’s GPT-3 (however impressive it seems) is just a fancy interpolator in the space of linguistic patterns. To test the validity of useful General Purpose Technology, an AI vs Human CTF would help make huge leaps. One of the best things about CTF’s is that they require creativity, deep understanding of software and sound on the fly strategic decision-making capabilities. Few years ago DARPA had a grad challenge which included a human designed AI vs AI CTF which the professors from my grad school won.13.
The grand challenge was quite impressive, but we can take it up a notch. An AI winning a human vs AI CTF would be the next ImageNet moment14 in the field of causal reasoning for software systems. When OpenAI beat humans at Dota-2, it was a very great leap to show how extremely stochastic and partially observable multi-agent problems can also have some good enough solution with neural networks in principle. If we want an exponential leap, we need AI’s beating humans in CTF’s. What this means that is one team deploy’s their AI solution and the human teams play against this AI counterpart in the CTF. The team representing the AI don’t get to change it during the game and AI has to discover the rules of the services during the game the way the human players do.
The other thing is that such CTF’s also need to evolve to ensure hard-enough problems and so that the AI solutions developed are not P-hacked15! Discovering ideas on how to make such a competition would require a lot of time and thought. A PhD would be the most perfect time to bring such a competition to life.
Conclusions
All the ideas listed here are few broad directions of research and schools of thought which excite me if I ever do a PhD. AI has become such a hype over the past 5-7 years and so many people are writing papers these days. We don’t know when we will reach a fully general purpose machine but the problems we need to solve only need to be solved once. The other aspect is that there are very few avenues aside academia where such deep problems can be given any time to think and discuss. I also think that many questions/thoughts addressed here require more than just 5/7 years one spends in a PhD but hey, If we ever want such big ideas like GPT we should aspire to find the right questions or schools of thought that help us get there!
Post Script
If you enjoyed reading about ideas on this blog and want to discuss more or correct me, then don’t be shy to reach out! I would love discussing more or correcting my understanding on such topics :)
Foot Notes
-
Sci-Genie is a search engine over CS ArXiv. I recently built it for getting a better grasp of what people are writing about and what directions of research are worth exploring. ↩
-
It’s called the manifold hypothesis. I am rehashing what I learned from a formal education. If I misunderstood please reach out and correct me. I would be really happy to learn what I have misunderstood. ↩
-
I don’t know the exact mathematical language to exactly state this. If you do, please help me better state this. ↩
-
Don’t Cite Me On That ↩
-
The Godfather’s of Deep Learnings are The Don’s of The AI Mafia. ↩
-
Interpretation and explanation is apparently very different for many people. In my understanding interpretation relates to what (training distribution, or network topology or test set) influenced the output. Explanation is about reasoning over the output of a complex model’s dynamics using post hoc methods (Like another model to explain in human understandable sense). Many people argue that model’s don’t need to have completely human understandable decisions. ↩
-
There here are many more aspects like Social Organization, Evolution which obviously were important for the development of intelligence. It would require a blog to just discuss those. ↩
-
Go with the flow. I know you need more than version control, but version control makes a huge difference. ↩ ↩2
-
Because with Git, we humans can together work better alone. ↩
-
Formulation from Decentralised Learning in Systems with Many, Many Strategic Agents. Formulation describes objective for N-Player Stochastic Game. ↩
-
The M-NE condition identifies strategic configurations in which no agent can improve their rewards by a unilateral deviation from their current strategy. ↩
-
This is info that comes from intuition after practicing the field for the past 6-7 year. Its not from a paper. Don’t cite this. ↩
-
The Security Faculty at ASU is raging. I got the best fundamental grasp into security after playing CTF’s organized by Dr. Fish Wang ↩
-
This is a term used quite frequently in the AI community. It relates to when AlexNet won the ImageNet challenge. When AlexNet won the challenge, it beat previous benchmarks by a considerable margin. The same way it happened for protein folding with AlphaFold2 ↩
-
Testing AI systems should require harder problems. To have better systems, we need continuously evolve the hardness of the problems tackled by the systems so that we don’t get stuck in local minima, and we don’t end up P-hacking. Dr. Arora recently wrote a paper proposing A Simple Estimate of Overfit to Test Data. Very interesting stuff! ↩